JS事件循环机制
前端|javaScript
发布于2024-03-19 最近修改2024-03-19
1229
0
Shimmer
JS事件循环机制
区分进程和线程
下面是一个简单的例子
- 进程是一个工厂,工厂有它的独立资源
- 工厂之间相互独立
- 线程是工厂中的工人,多个工人协作完成任务
- 工厂内有一个或多个工人
- 工人之间共享空间
与系统联系起来如下
- 工厂的资源 -> 系统分配的内存(独立的一块内存)
- 工厂之间的相互独立 -> 进程之间相互独立
- 多个工人协作完成任务 -> 多个线程在进程中协作完成任务
- 工厂内有一个或多个工人 -> 一个进程由一个或多个线程组成
- 工人之间共享空间 -> 同一进程下的各个线程之间共享程序的内存空间(包括代码段、数据集、堆等)
用较为官方的术语描述一遍:
- 进程是cpu资源分配的最小单位(是能拥有资源和独立运行的最小单位)
- 线程是cpu调度的最小单位(线程是建立在进程的基础上的一次程序运行单位,一个进程中可以有多个线程)
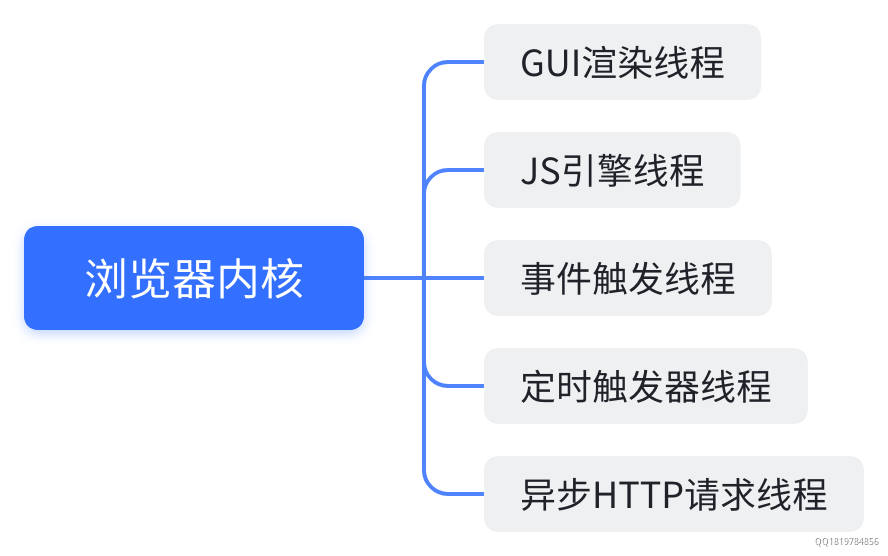
浏览器内核(渲染进程)
GUI渲染线程
- 当浏览器收到响应的html后,该线程开始解析HTML文档构建DOM树,解析CSS文件构建CSSOM,合并构成渲染树,并计算布局样式,绘制在页面上(该处可深挖的坑,HTML解析规则,CSS解析规则,渲染流程细节)
- 当界面样式被修改的时候可能会触发reflow(回流)和repaint(重绘),该线程就会重新计算,重新绘制,是前端开发需要着重优化的点(值得注意的是react和vue都使用了虚拟DOM)
JS引擎线程
JS内核,也称JS引擎(例如V8引擎),负责处理执行javascript脚本程序,
由于js是单线程(一个Tab页内中无论什么时候都只有一个JS线程在运行JS程序),依靠任务队列来进行js代码的执行,所以js引擎会一直等待着任务队列中任务的到来,然后加以处理。
事件触发线程
归属于渲染(浏览器内核)进程,不受JS引擎线程控制。主要用于控制事件(例如鼠标,键盘等事件),当该事件被触发时候,事件触发线程就会把该事件的处理函数添加进任务队列中,等待JS引擎线程空闲后执行
定时触发器线程
传说中的setInterval与setTimeout所在线程
浏览器的定时器并不是由JavaScript引擎计数的,因为JavaScript引擎是单线程的, 如果处于阻塞线程状态就会影响计时的准确,因此通过单独的线程来计时并触发定时器,计时完毕后,满足定时器的触发条件,则将定时器的处理函数添加进任务队列中,等待JS引擎线程空闲后执行。
W3C在HTML标准中规定,规定要求setTimeout中低于4ms的时间间隔算为4ms
异步HTTP请求线程
当XMLHttpRequest连接后,浏览器会新开的一个线程,当监控到readyState状态变更时,如果设置了该状态的回调函数,则将该状态的处理函数推进任务队列中,等待JS引擎线程空闲后执行
GUI渲染线程与JS引擎线程是互斥的,当JS引擎执行时GUI线程会被挂起(相当于被冻结了),GUI更新会被保存在一个队列中等到JS引擎空闲时立即被执行。所以如果JS执行的时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞。
浏览器对同一域名请求的并发连接数是有限制的,Chrome和Firefox限制数为6个
Preview
浏览器内核中线程之间的关系
1、GUI渲染线程与JS引擎线程互斥
由于JavaScript是可操纵DOM的,如果在修改这些元素属性同时渲染界面(即JS线程和UI线程同时运行),那么渲染线程前后获得的元素数据就可能不一致了。
因此为了防止渲染出现不可预期的结果,浏览器设置GUI渲染线程与JS引擎为互斥的关系,当JS引擎执行时GUI线程会被挂起,
GUI更新则会被保存在一个队列中等到JS引擎线程空闲时立即被执行。
2、JS阻塞页面加载
从上述的互斥关系,可以推导出,JS如果执行时间过长就会阻塞页面。
譬如,假设JS引擎正在进行巨量的计算,此时就算GUI有更新,也会被保存到队列中,等待JS引擎空闲后执行。
然后,由于巨量计算,所以JS引擎很可能很久很久后才能空闲,自然会感觉到巨卡无比。
所以,要尽量避免JS执行时间过长,这样就会造成页面的渲染不连贯,导致页面渲染加载阻塞的感觉。
3、WebWorker
WebWorker
web worker 是运行在后台的 JavaScript,独立于其他脚本,不会影响页面的性能。您可以继续做任何愿意做的事情:点击、选取内容等等,而此时 web worker 在后台运行。
Web Workers 和 DOM
由于 web worker 位于外部文件中,它们无法访问下列 JavaScript 对象:
window 对象
document 对象
parent 对象
浏览器渲染流程
提起这个问题不得不引入我们说熟悉的另一个问题,从输入url地址到页面相应都发生了什么?
查询缓存
查询缓存
从输入url按下回车后,我们进入了第一步就是 DNS 解析过程,首先需要找到这个 url 域名的服务器 ip,为了寻找这个 ip,浏览器首先会寻找缓存,查看缓存中是否有记录缓存的查找记录为:浏览器缓存 -> 系统缓存 -> 路由器缓存,缓存中没有则查找系统的 hosts 文件中是否有记录。
DNS解析
如果没有缓存则查询 DNS 服务器,得到服务器的 ip 地址后,浏览器根据这个 ip 以及相应的端口号发送连接请求;如果DNS服务器中没有解析成功,他会向上一步获得的顶级DNS服务器发送解析请求。
建立TCP连接(3次握手)
服务端新建套接字,绑定地址信息后开始监听,进入LISTEN状态(侦听状态)。客户端新建套接字绑定地址信息后调用connect,发送连接请求SYN,并进入SYN_SENT状态,等待服务器的确认。
服务端一旦监听到连接请求,就会将连接放入内核等待队列中,并向客户端发送SYN和确认报文段ACK,进入SYN_RECD状态。
客户端收到SYN+ACK报文后向服务端发送确认报文段ACK,并进入ESTABLISHED状态,开始读写数据。服务端一旦收到客户端的确认报文,就进入ESTABLISHED状态,就可以进行读写数据了。
客户端发起http请求
http是基于tcp的,所以只有在建立了tcp以后,客户端才能向服务器发起http请求。这个请求报文会包括这次请求的信息,主要是请求方法,请求说明和请求附带的数据,并将这个 http 请求封装在一个 tcp 包中;这个 tcp 包也就是会依次经过传输层,网络层, 数据链路层,物理层到达服务器,服务器解析这个请求来作出响应;返回相应的 html 给浏览器;
服务器处理请求
后端从在固定的端口接收到TCP报文开始,它会对TCP连接进行处理,对HTTP协议进行解析,并按照报文格式进一步封装成HTTP Request对象,供上层使用。
服务器响应请求
服务器收到了我们的请求,也处理我们的请求,到这一步,它会把它的处理结果返回,也就是返回一个HTPP响应。
浏览器解析html
浏览器渲染引擎从网络层取得请求的文档,一般情况下文档会分成 8KB 大小的分块传输。
浏览器渲染引擎从上往下执行代码(包括HTML,CSS和JS),解析html生成DOM树,同时解析CSS代码生成css rule tree,同时把DOM tree和css rule tree合并生成render tree,同时还会去请求另一些资源,所以渲染引擎会同时干很多事,迫不及待地把内容渲染出来,如果后面的代码会改变之前的样式,会引起回流和重绘。
具体渲染流程见下图

Preview
断开TCP连接(4次挥手)
➡️
客户端主动调用close时,向服务端发送结束报文段FIN报,同时进入FIN_WAIT1状态;
服务器会收到结束报文段FIN报,服务器返回确认报文段ACK并进入CLOSE_WAIT状态,此时如果服务端有数据要发送的话,客户端依然需要接收。客户端收到服务器对结束报文段的确认,就会进入到FIN_WAIT2状态,开始等待服务器的结束报文段;
服务器端数据发送完毕后,当服务器真正调用close关闭连接时,会向客户端发送结束报文段FIN包,此时服务器进入LAST_ACK状态,等待最后一个ACK的带来;
客户端收到服务器发来的结束报文段, 进入TIME_WAIT, 并发出送确认报文段ACK;服务器收到了对结束报文段确认的ACK,进入CLOSED状态,断开连接。而客户端要等待2MSL的时间,才会进入到CLOSED状态。
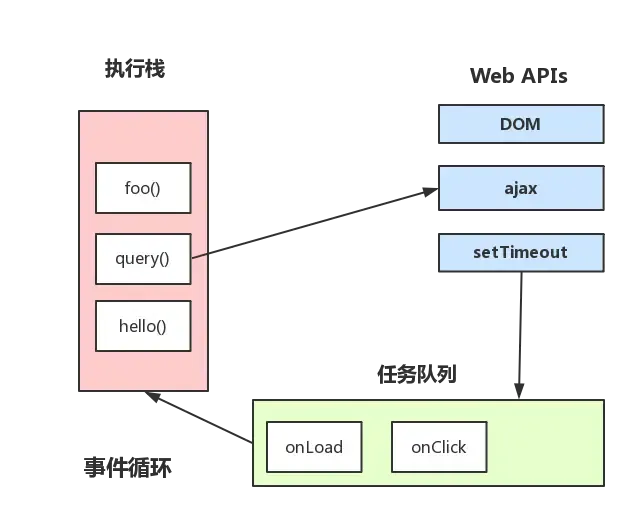
Event Loop -> JS事件循环机制
JS分为同步任务和异步任务
同步任务都在主线程上执行,形成一个执行栈
主线程之外,事件触发线程管理着一个任务队列,只要异步任务有了运行结果,就在任务队列之中放置一个事件。
一旦执行栈中的所有同步任务执行完毕(此时JS引擎空闲),系统就会读取任务队列,将可运行的异步任务添加到可执行栈中,开始执行。

Preview
为什么定时器不能准时执行?
JS是单线程,所以异步事件(比如鼠标点击和定时器)仅在线程空闲时才会被调度运行,代码执行时异步事件任务会按照将它们添加到队列的顺序执行,而setTimeout() 的第二个参数只是告诉JS再过多长时间把当前任务添加到队列中。如果队列是空的,那么添加的代码会立即执行;如果队列不是空的,那么它就要等前面的代码执行完了以后再执行。
浏览器不会对同一个setInterval处理程序多次添加到待执行队列。
此处可以理解为,当任务队列中已经存在相同id的定时器任务时,后面添加进来的将会被废弃。
注:一般的话,路由跳转无法销毁setInterval和setTimeout等全局方法(因为它们属于window的方法),所以在使用vue和react native、react等框架时,路由的跳转之前,要清空定时器。
Preview
JavaScript复制代码setTimeout(function(){ console.log('start'); }, 0); console.log('end');
此处预留一个小问题,以上代码是如何执行的呢?先打印哪个?
接下来我们开始了解一下,宏任务与微任务。
宏任务与微任务

Preview
- 执行一个宏任务(栈中没有就从事件队列中获取) 执行过程中如果遇到微任务,就将它添加到微任务的任务队列中
- 宏任务执行完毕后,立即执行当前微任务队列中的所有微任务(依次执行)
- 当前宏任务执行完毕,开始检查渲染,然后GUI线程接管渲染
- 渲染完毕后,JS线程继续接管,开始下一个宏任务(从事件队列中获取)
下面我们来分析几个代码片段的执行结果,看看是否真正掌握了宏任务与微任务的运行机制。
JavaScript复制代码console.log('script start'); setTimeout(function() { console.log('setTimeout'); }, 0); Promise.resolve().then(function() { console.log('promise1'); }).then(function() { console.log('promise2'); }); console.log('script end');
JavaScript复制代码console.log('script start'); setTimeout(function() { console.log('timeout1'); }, 10); new Promise(resolve => { console.log('promise1'); resolve(); setTimeout(() => console.log('timeout2'), 10); }).then(function() { console.log('then1') }) console.log('script end');
总结:宏任务与微任务都属于JS的异步任务
- 宏任务(macrotask): 异步 Ajax 请求、 setTimeout、setInterval、 文件操作 其它宏任务
- 微任务(microtask): Promise.then、.catch 和 .finally process.nextTick 其它微任务
补充:nodeJs中的事件循环
➡️
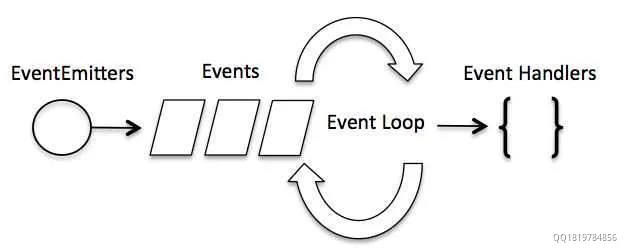
事件驱动程序
- Node.js 使用事件驱动模型,当web server接收到请求,就把它关闭然后进行处理,然后去服务下一个web请求。
- 当这个请求完成,它被放回处理队列,当到达队列开头,这个结果被返回给用户。
- 这个模型非常高效可扩展性非常强,因为 webserver 一直接受请求而不等待任何读写操作。(这也称之为非阻塞式IO或者事件驱动IO)
- 在事件驱动模型中,会生成一个主循环来监听事件,当检测到事件时触发回调函数。
整个事件驱动的流程就是这么实现的,非常简洁。有点类似于观察者模式,事件相当于一个主题(Subject),而所有注册到这个事件上的处理函数相当于观察者(Observer)。
 Preview
Preview
目录